




Topics
ここでは(大町)・能勢研で扱っている研究テーマの一部を紹介します。
・アニメ調キャラクター顔画像に適するクロスモーダル音声合成
・End-to-End歌声合成における楽譜情報を活用した韻律予測に関する研究
・自己教師あり学習に基づく声質変換
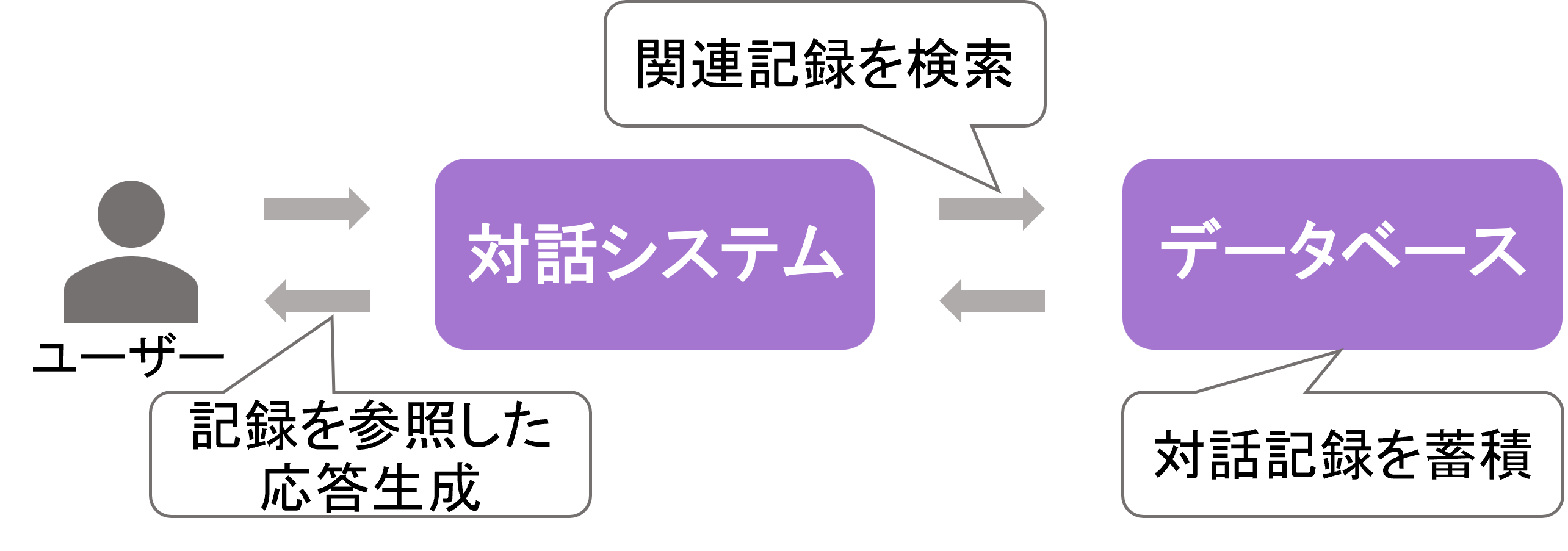
・対話システムの過去対話記録検索に関する研究
・クラウド障害時に対応可能な音声対話システムの検討
・少数言語学習のための音声認識を使用しない音声対話システムに関する研究
・オンライン講義に向けた学習支援対話エージェントの開発
・オンライン学習における知覚刺激を用いた注意度向上手法に関する研究
・実応用に向けたドメインに頑健な音声感情認識の実現
・劣化したレコード音源の修復
・日本語Audio Captioningモデルの構築
・環境音データセットの構築
・視覚的・意味的特徴抽出に基づく内容ベース漫画推薦システムに関する研究
音声・歌声の合成・変換
アニメ調キャラクター顔画像に適するクロスモーダル音声合成
近年の機械学習によるテキスト音声合成(TTS)技術は、深層学習モデルの進展により大幅に向上しており、Style-Bert-VITS2(SBV2)などの最近のモデルでは、目標話者の音声からその特徴を捉えた高品質な音声を合成できるようになっている。しかし、新規アニメ・ゲームなどへの用途を考慮し、実在しないキャラクターに対して適切な声を自動的に割り当てることは難しい。そのため、キャラクターに適する話者性の音声を合成するTTS技術が必要となる。 そこで、本研究では顔画像から新規キャラクターの話者性を推測し、そのキャラクターに適する話者性の音声を合成するTTSを構築することを目標としている。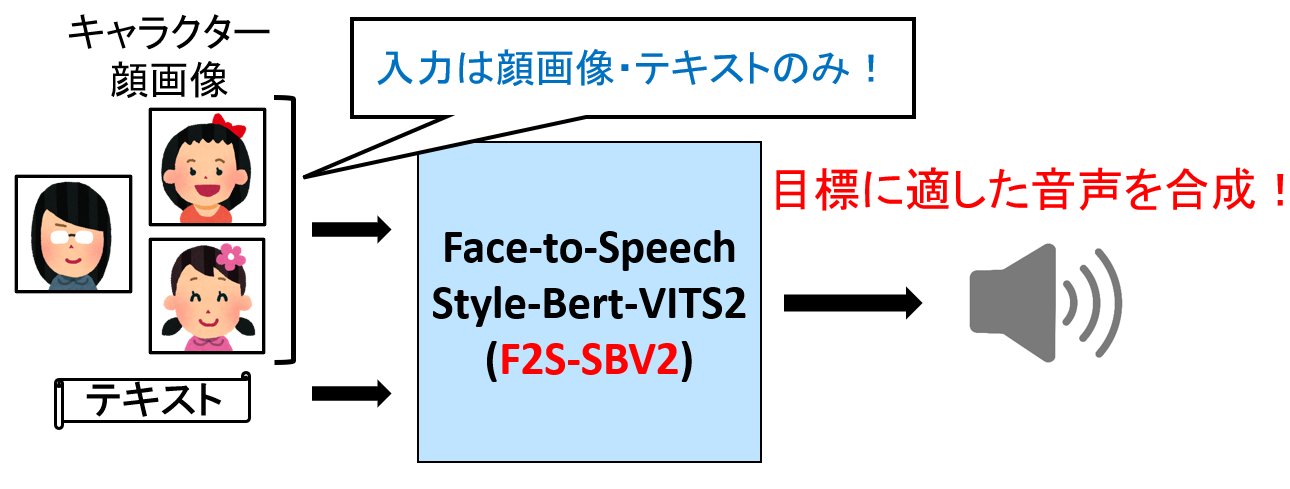
- Kikuchi, H., Nose, T., Kobayashi, S., Hayashizaki, Y., Hashimoto., K, & Ito, A., "JAFS: Construction of Japanese Anime Face and Speech Dataset for Cross-Modal Speech Synthesis," In Proc.IEEE GCCE 2025, pp. 785-786, 2025.
- 菊池遥斗,能勢隆,小林清流,林崎由,橋本佳,伊藤彰則, "F2S-SBV2:任意のアニメ調キャラクター顔画像に適した話者性を有するテキスト音声合成の検討", 情報処理学会研究報告, 2025-SLP-156, pp. 1–7, 2025.
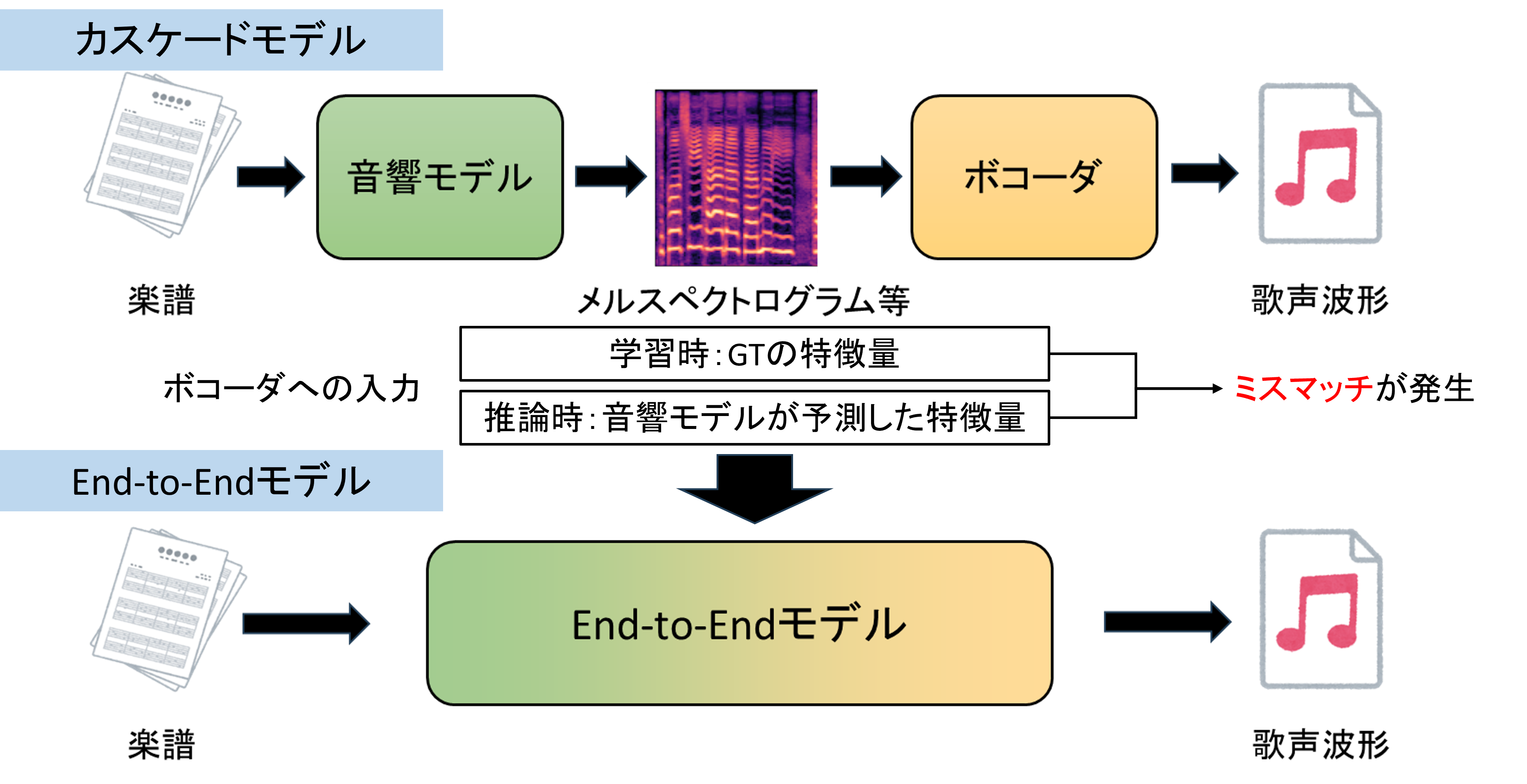
End-to-End歌声合成における楽譜情報を活用した韻律予測に関する研究
歌声合成は、楽譜データから歌声を生成する技術であり、エンターテインメント分野で広く活用されている。 従来は「音響モデル」と「ボコーダ」を独立して学習するカスケードモデルが一般的であったが、ボコーダの学習時と推論時の入力の違いにより品質が低下する課題があった。これに対し、近年登場したEnd-to-End (E2E) モデルはこの問題を解消し、高い合成品質を実現している。 しかし、既存のE2Eモデルは楽譜情報を十分に活用できておらず、「ピッチ」や「リズム」の再現性が低いという課題が残っている。本研究では、楽譜の音高やタイミング情報を基にその差分を予測する手法やデータ拡張手法をE2Eモデルに導入し、ピッチ・リズム推定精度を向上させたE2E歌声合成モデルの実現を目指す。
自然歌声の例
合成歌声の例
- Oono Tomoki, Takashi Nose, and Akinori Ito. "Duration Estimation Based on a Time-Lag Model in End-to-End Singing Voice Synthesis." 2025 IEEE 14th Global Conference on Consumer Electronics (GCCE). IEEE, 2025.
- 大野友暉, 能勢隆, 小林清流, 伊藤彰則, "End-to-End歌声合成における楽譜情報を利用した韻律のモデル化の検討", 日本音響学会2025年秋季研究発表会講演論文集, pp. 1207-1210, 2024.
自己教師あり学習に基づく声質変換
声質変換技術とは、ある音声の内容は保持して、話者性、つまり声のアイデンティティのみを変える技術である。近年、声質変換において自己教師あり学習(SSL)を活用した手法の研究が盛んに行われている。SSLを用いた手法は従来の手法と比較して高品質な音声を誰からであっても合成可能であるという特徴があるが、これは音声SSLモデルが話者によらない特徴量を抽出することによって実現される。話者の変化に強いモデルを使うことにより、目標話者により近い音声を合成することが可能であるが、現状最も話者の変化に強いモデルを用いても、完璧に変換するのは難しい。そこで本研究では、音声SSLモデルを声質変換向けに改善し、より高品質な変換を実現することを目的としている。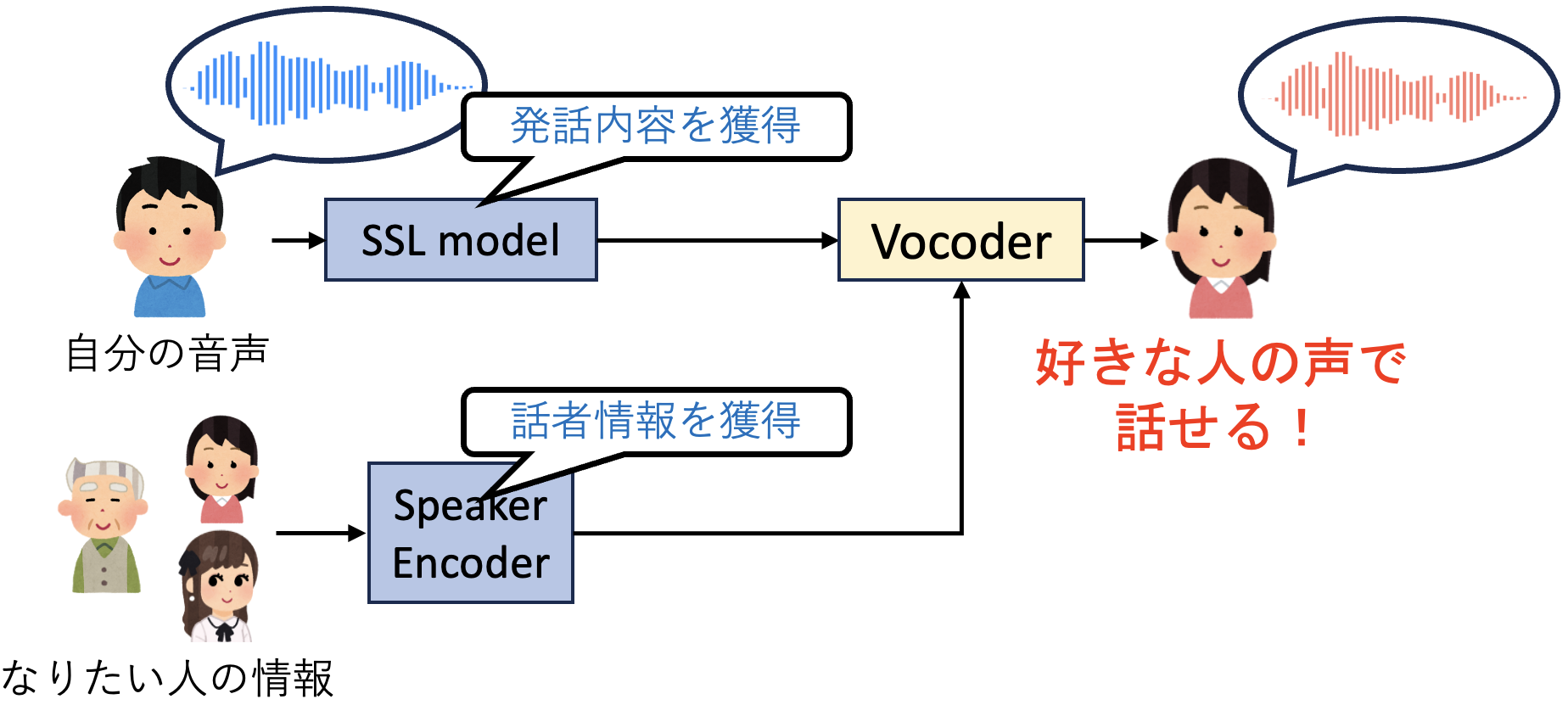
元音声
GT
HuBERT
WavLM
ContentVec
- Rin Yamashita, Takashi Nose, Sumiharu Kobayashi, Akinori Ito. "Analysis of Pitch-Shift Effects on Self-Supervised Speech Representations." 2025 IEEE 14th Global Conference on Consumer Electronics (GCCE). IEEE, 2025.
- 山下凜、能勢隆、小林清流、伊藤彰則、"自己教師あり学習に基づく声質変換におけるモデルと性別の影響分析", 情報処理学会研究報告, 2025-SLP-156, pp. 1–8, 2025.
対話システム
対話システムの過去対話記録検索に関する研究
近年、対話システムの利用が広く普及しており、長期的な対話への需要も高まっている。一方で、多くの対話システムでは単一セッションでの最適化にとどまっているという課題がある。そこで、過去の対話記録を適切に参照しつつ応答を生成することで、ユーザーとの持続的な関係を構築できるような長期記憶機能を備えた対話システムの研究が進められている。本研究では、対話記録の検索の最適化を目指す。まず、キーワードやベクトル検索等の手法を比較し、記憶の性質に応じた最適な手法を探る。また、検索クエリに含める対話履歴長の影響を検証する。これらを通じ、対話の一貫性と発展性を両立するシステム構築を目指す。
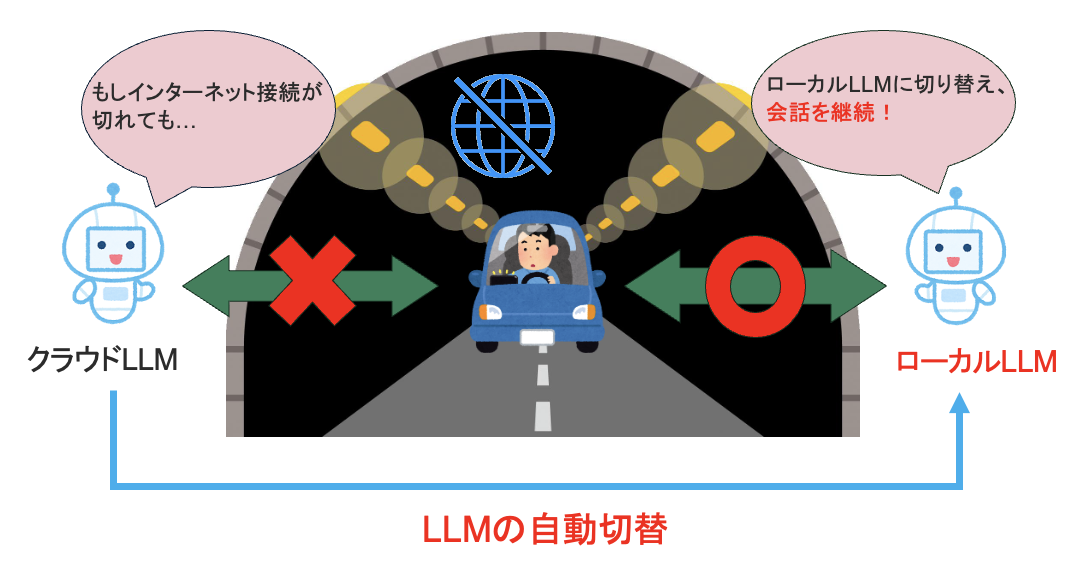
クラウド障害時に対応可能な音声対話システムの検討
近年、大規模言語モデル(LLM)の導入により音声対話システムの応答品質が大きく向上しており、特にクラウド上で動作するLLMは大規模パラメータによる高精度な応答生成を可能にしており、このクラウドLLMを用いた構成は実用的な技術として注目されている。その一方で、自動車内におけるクラウド依存型のシステムは通信切断などの環境的制約が弱点として挙げられる。本研究ではクラウドとの接続が断たれた際に、ローカル上で動作するLLMへと自動的に切替を行うことで音声対話の継続が実現する車載システムの構築を目指す。具体的には、車載対話に適したローカルLLMの選定や、発話内容理解度などの評価を行うことで、より実用性の高いモデル切替システムの構築を目標としている。
少数言語学習のための音声認識を使用しない音声対話システムに関する研究
近年、話者数の少ない少数言語において、言語学習や対話を通じて新たな話者を育成する「言語活性化」を支援する手法としてComputer-Assisted Language Learning(CALL)が注目されている。一方、従来の音声対話型システムは音声認識や音声合成に大量の音声データを必要とするため、適用が困難である。本研究では、少量の音声データでも実現可能な仕組みとして、音声認識・音声合成を用いず、音声サンプル間の類似度に基づいて直接応答を行うサンプルベース音声対話システム(SBSDS)を新たに提案する。具体的には、音声の内容に注目した特徴抽出や特徴の量子化を用いた効率的な発話選択により、少数言語における実用的な言語学習支援システムを構築し、その有効性を実証実験により示す。
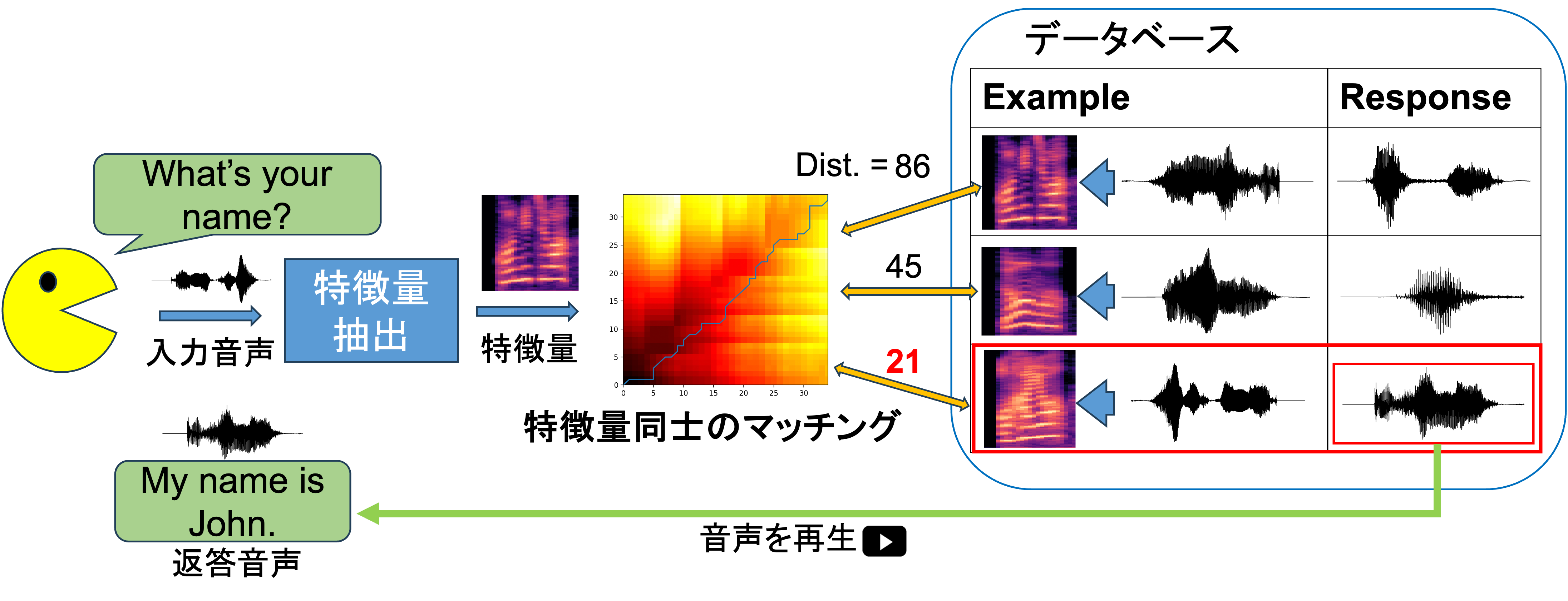
提案する音声対話システム「SBSDS」の構造
- Koshikawa, T., Ito, A., & Nose, T., "Fast and speaker-independent utterance selection for ASR-free CALL systems of minority languages," In Proc. APSIPA ASC 2025, pp. 825 - 830, 2025. (英語)
- 越川崇貴, 伊藤彰則, 能勢隆, "音声認識を用いない少数言語学習支援システムにおける話者非依存かつ高速な発話選択の検討," APSIPA ASC 2025 論文集, pp. 825 - 830, 2025. (日本語)
学習支援システム
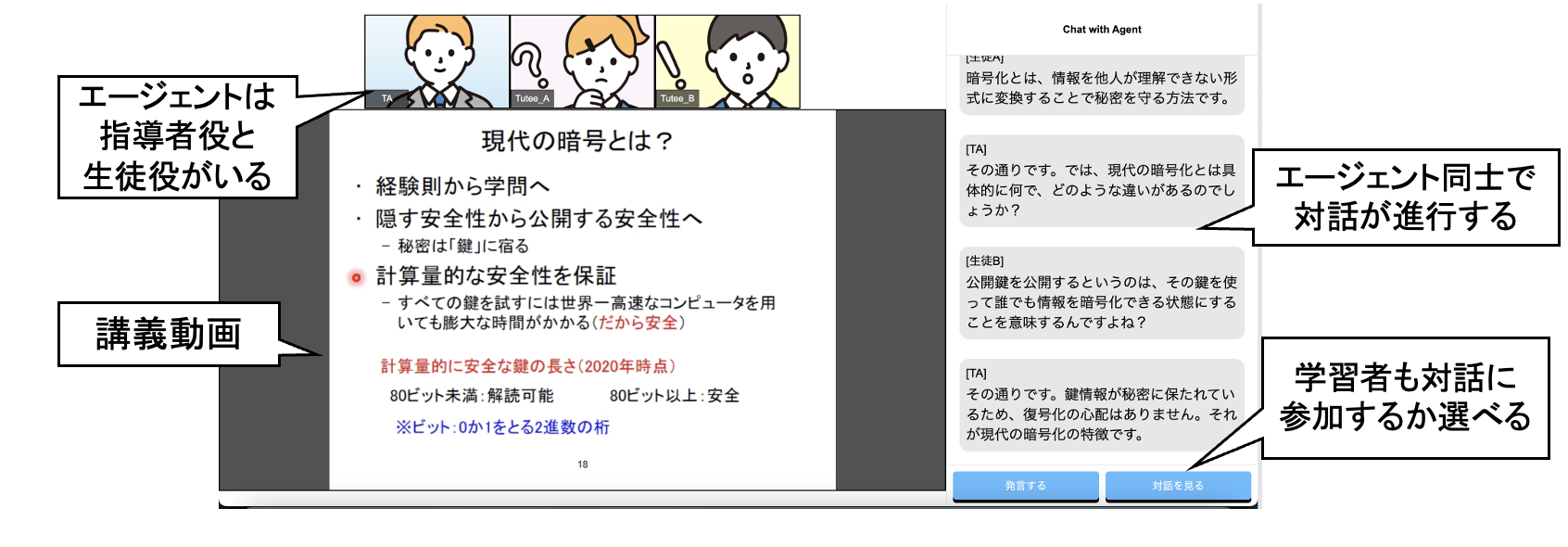
オンライン講義に向けた学習支援対話エージェントの開発
近年、録画された講義動画を用いた学習が広く普及している。その中で、講義視聴中の学習者に対して理解度の確認や質問応答を行う仮想的な学習仲間である「学習エージェント」を導入することで、学習者の理解度や集中度を向上させる取り組みが注目されている。一方で、従来の研究では、エージェントの発話内容や介入のタイミングを人手で設計する必要があり、導入コストが高いという課題が存在する。本研究では、講義動画に学習エージェントを自動的に導入する仕組みの実現を目指す。具体的には、動画の音声や画面情報といったマルチモーダル情報を活用して講義の重要箇所や内容の区切りを自動的に検出し、大規模言語モデル(LLM)を用いて学習者との対話を生成する。さらに、自動生成された学習エージェントを組み込んだ学習支援システムを構築する。
- Naito, H., Ito, A., & Nose, T., "Automatic Dialogue Generation for Learning Agents in Lecture Videos Using LLMs," In Proc. IEEE GCCE 2025, pp. 1256-1259, 2025.
- 内藤陽大, 伊藤彰則, 能勢隆, "音声書き起こしと画像キャプションを用いたLLMによる講義動画の分割手法の検討", 2025年映像情報メディア学会冬季大会講演予稿集, pp. 1-2, 2025.
オンライン学習における知覚刺激を用いた注意度向上手法に関する研究
オンデマンド講義の普及に伴い、受講者の持続的注意の低下による学習効果の減少が課題となっている。しかし、警告音等の明示的な介入は学習プロセスを中断させ、受講者の学習意欲を阻害することが報告されている。 そこで本研究では、知覚刺激を用いて非明示的に注意を喚起する手法の実現を目指す。具体的には、視線や顔の向き、心拍数などから受講者の注意状態を推定し、注意低下時に「音量」「輝度」「振動」といった物理的刺激をフィードバックする。これにより、受講者に不快感や認知的負荷を与えず、講義への注意を回復および維持させる手法の有効性を検証している。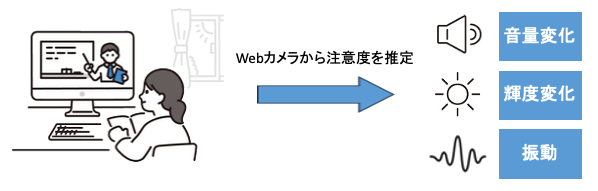
音声感情認識
実応用に向けたドメインに頑健な音声感情認識の実現
音声感情認識とは「音声に含まれる話者の感情を推定する技術」のことを指す。自然なヒューマン・コンピュータ・インタラクションを実現するのに不可欠な技術であり、近年では深層学習モデルを用いた手法が多く提案されている。しかし、従来の手法では、録音環境・話者・言語などが異なるためモデルが学習していない「ドメイン外」のデータに対して大きく性能が低下することが報告されている。本研究では、音声感情認識の実応用に向けて、ドメインの違いに頑健な「感情基盤モデル」を実現することを目的とする。複数の感情音声コーパスを用いて大規模な事前学習を行う「マルチコーパス学習」や、同時に複数の課題を学習させることでモデルの性能を高める「マルチタスク学習」などの手法を通して、「どのような環境でも使える感情基盤モデル」を構築する。
- Y. Hayashizaki, T. Nose, S. Kobayashi, S. Fukayama and A. Ito, "PUNSER: Large-Scale Pre-Trained and Unified Model for Practical Speech Emotion Recognition," In Proc. APSIPA ASC 2025, pp. 747-752, 2025.
- 林崎由, 能勢隆, 駒形晃太, 伊藤彰則, "マルチコーパス学習に基づくドメインロバスト音声感情認識の検討," 日本音響学会2024年秋季研究発表会講演論文集, pp. 1107-1110, 2024.
音楽情報処理
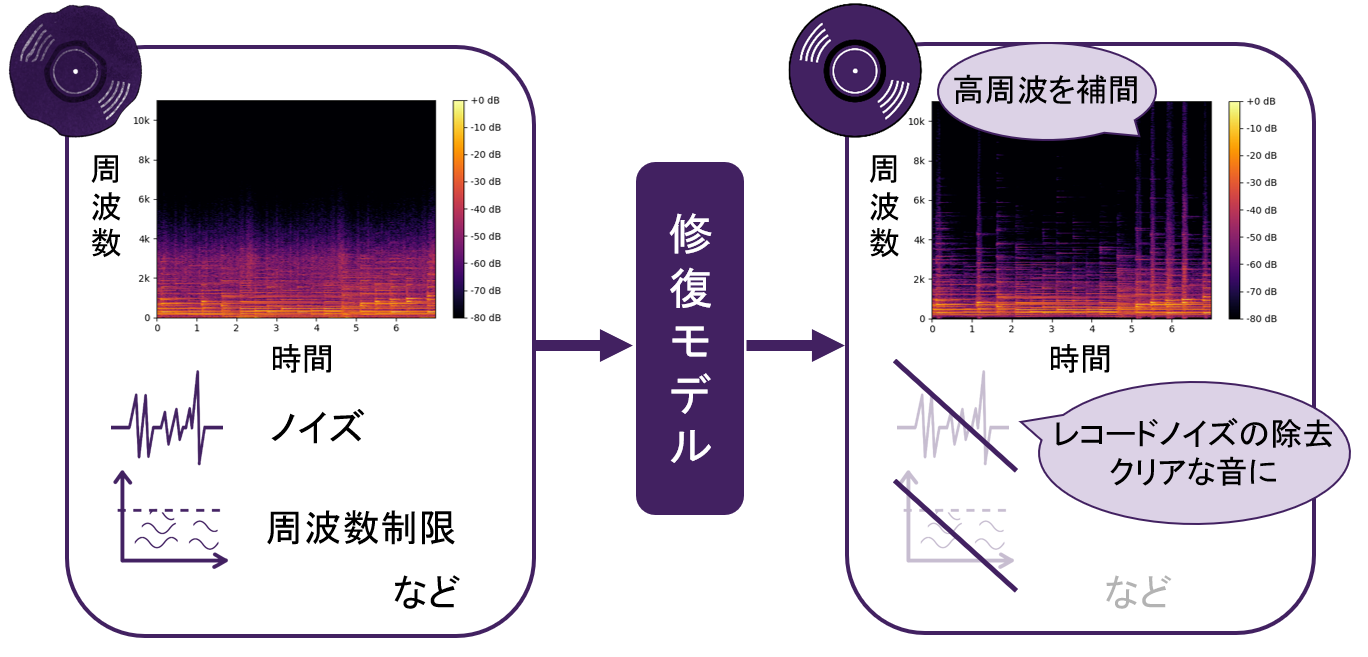
劣化したレコード音源の修復
1950年以前に主流であった78回転盤レコードには、当時の演奏様式や音楽文化を伝える貴重な音源が数多く残されている。しかしこれらの録音は劣化が激しく、周波数帯域の制限やノイズが含まれる。近年では、深層学習を用いてこのような歴史的価値の高いレコード音源を修復し、現代でも聴きやすくアクセスが容易な音へと再生させる研究が注目されている。レコード録音の修復では、ノイズ除去や帯域拡張に加え、どのような劣化処理が施されているかが事前に分からないブラインドタスクであるなど、複合的なタスクが要求される。本研究では、深層学習モデルを活用し、複数の修復タスクを組み合わせた柔軟なパイプラインの設計と性能向上、単一モデル化に取り組んでいる。
音声・音の認識
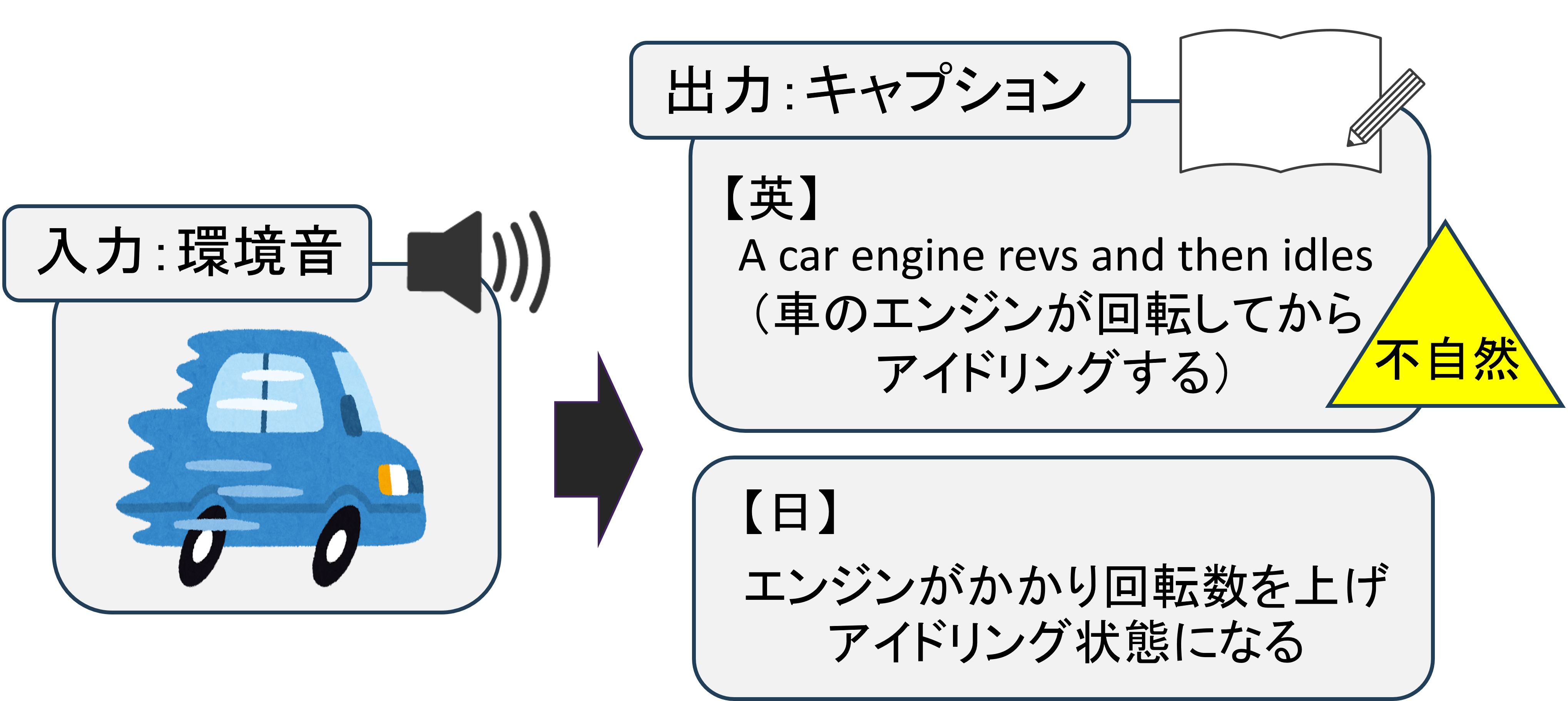
日本語Audio Captioningモデルの構築
人は身近な状況を把握する要素の一つとして、環境音を活用している。例えば、自分の後ろから車が近づく音が聞こえたとき、私たちは自分の後方を確認し、身の安全を保つ行動をとる。このような環境音による周囲の状況把握を、近年の大規模言語モデル(LLM)や深層学習を用いて計算機に実行させる研究が行われている。このような環境音認識タスクの1つであるAudio Captioningは、入力された環境音から推測される情景描写をキャプションとしてテキストベースで出力する。しかし、Audio Captioningモデルは英語圏特有の環境音を使用した学習や英語のキャプションのみの出力などのように、文化や言語に依存することが多い。このような多言語拡大に関する問題を解決するため、本研究では日本語対応のAudio Captioningモデルの構築を検討している。
環境音データセットの構築
これまでの研究では、季節ごとに聞こえる音の種類や音量の違いが環境評価に影響を及ぼすことや、騒音レベルが場所特有の要因によって変化することが報告されている。しかし、こうした知見の多くは特定の地点や条件で取得された音データに基づく分析に留まっており、季節・時間帯・天候といった要因がどのように変動しているのかを十分に捉えられていない。そのため、環境音の変動性を体系的に扱えるデータセットの不足が課題となっている。 そこで本研究では、季節、時間帯、天候、場所といった複数の要因による環境音の変化を捉えた環境音データセットの構築を目的とする。長期間にわたる音響データの収集を行うことで、環境音が持つ変動を記録し、条件ごとの特徴を明らかにする。さらに、実際に収集したデータを用いて、各条件が音響特性に与える影響を分析し、環境音を用いた環境認識・評価への応用可能性を検討する。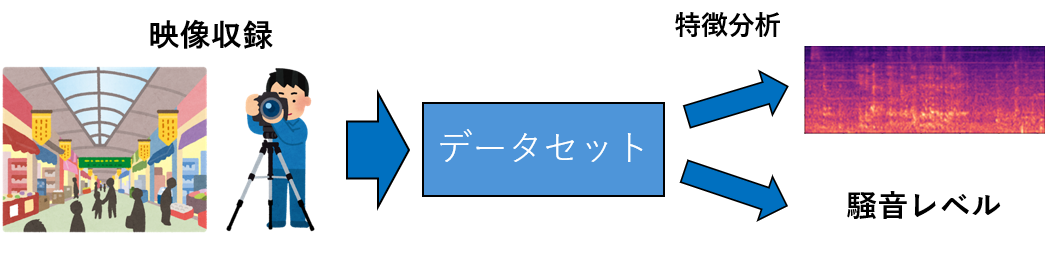
- Sota Sugaya, Akinori Ito & Takashi Nose, "Study Toward a Multi-location Environmental Sound Dataset Including Temporal Environmental Changes", Proceedings of 2025 International Workshop on Emerging ICT, pp. 1-3.
- 菅谷綜太, 伊藤彰則, 能勢隆, "季節・天候・時間の変化を捉えた複数地点の環境音データセットの構築", 令和8年東北地区若手研究者研究発表会講演資料, pp. 109-110.
その他
視覚的・意味的特徴抽出に基づく内容ベース漫画推薦システムに関する研究
近年、漫画のデジタル配信拡大により、膨大な作品から読者が好みの作品を見つけるための推薦システムの重要性が高まっている。本研究では、漫画原稿の情報を元に推薦を行う「内容ベース漫画推薦システム」を提案する。具体的には、原稿画像に基づき「年代」や「ジャンル」などの複数の観点に基づいた視覚的特徴を抽出する手法と、LLMを用いて物語の感情変化を捉える「感情アーク(感情の起伏)」を抽出する意味的なアプローチを統合する。これにより、ジャンルや年代、さらには読後感の類似性に基づいた多角的な漫画推薦を可能にすることを目指している。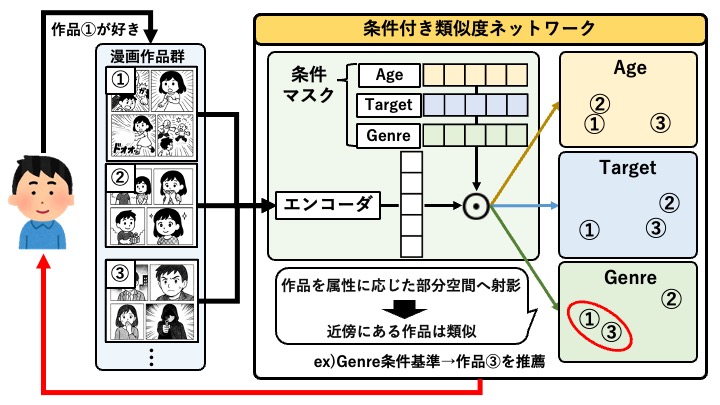
- Rei Takahashi, Takashi Nose, Akinori Ito, "内容ベース漫画推薦の実現に向けた条件付き画像類似度ネットワークの検討", FIT2025 第24回情報科学技術フォーラム講演論文集, pp. 193-194.